Hive
![[object Object]](/_next/static/images/hero-df609063efda5739724de115f2fe0ff0.png)
Hive Vision
Language Model
Hive Vision
Language Model
Hive Vision-Language Model (VLM) can turn images—or image & text pairs—into plain-language answers and structured JSON in one call. Moderate, tag, or detect subtle elements without stitching together multiple models.
Shifting the paradigm for content understandingHive Vision Language Model turns a plain-text prompt into rapid tagging, moderation, and detection — No retraining. No thresholds. Clear results.
Shifting the paradigm for content understandingHive Vision Language Model turns a plain-text prompt into rapid tagging, moderation, and detection — No retraining. No thresholds. Clear results.
One model, broad use cases
Replace dozens of siloed classifiers with a single, promotable VLM.
Understands deep context
Reads images and text together to catch edge cases that humans often miss.
Enforce your policies with flexibility
Write or edit your guidelines in natural language and roll them out in seconds.
When Hive VLM is the right choice
When Hive VLM is the right choice
Choose VLM when you need flexible labels and easy policy tweaks. Use our pre-trained classifiers when fixed classes and accuracy are top priorities.
Choose VLM when you need flexible labels and easy policy tweaks. Use our pre-trained classifiers when fixed classes and accuracy are top priorities.

Prompt-level control, tuned to your goals
Prompt-level control, tuned to your goals
Hive VLM now supports Bias Tuning, giving teams more control over how specific classes are returned. By increasing or decreasing class weights directly in the prompt, teams can better align VLM behavior with their precision and recall goals.
Use Bias Tuning to reduce false positives, increase recall for high-priority policy areas, or adapt classification behavior across different policies.
Hive VLM now supports Bias Tuning, giving teams more control over how specific classes are returned. By increasing or decreasing class weights directly in the prompt, teams can better align VLM behavior with their precision and recall goals.
Use Bias Tuning to reduce false positives, increase recall for high-priority policy areas, or adapt classification behavior across different policies.
Intuitive LLM-based content understanding
Intuitive LLM-based content understanding
Don’t just trust us, test us
Don’t just trust us, test us
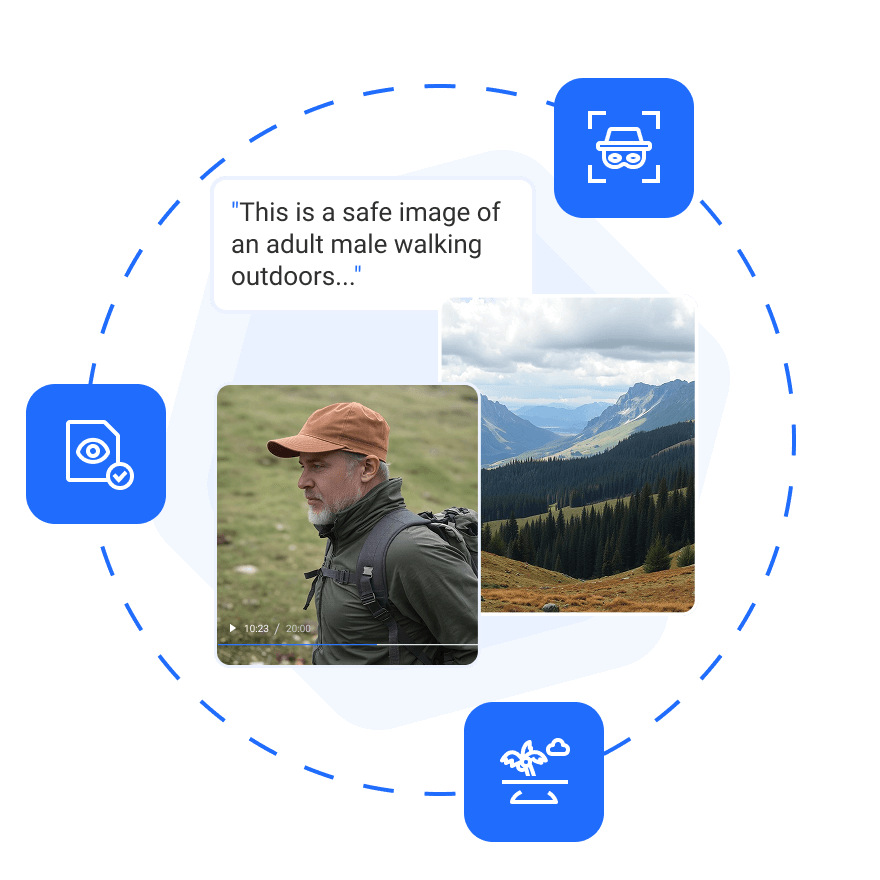
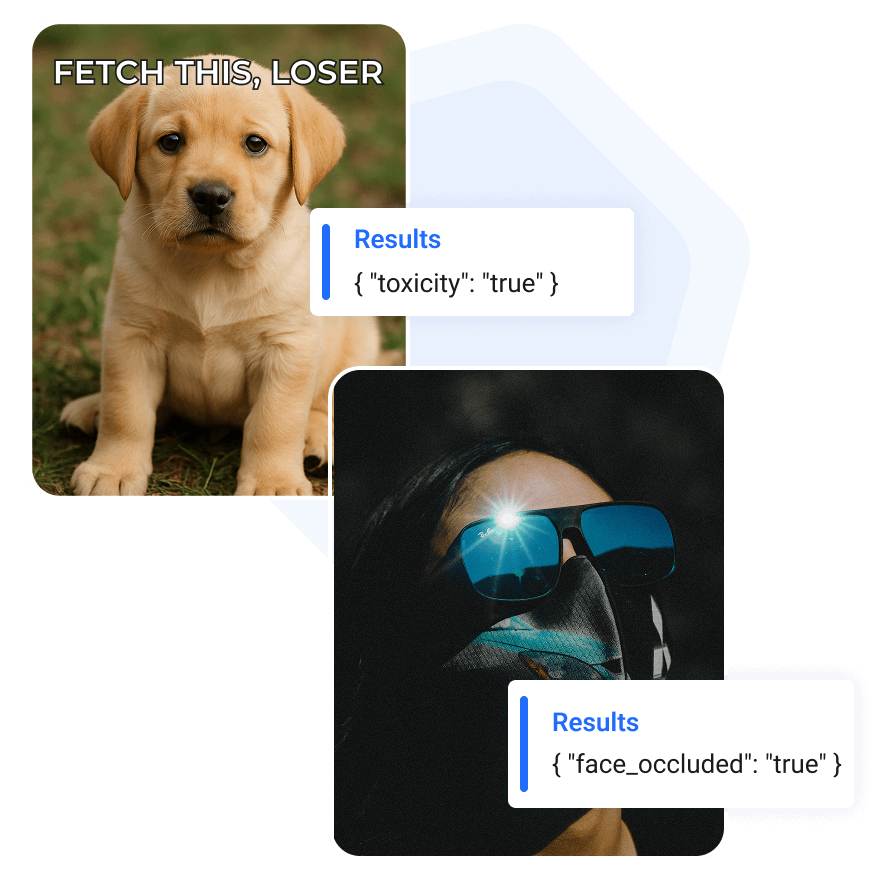
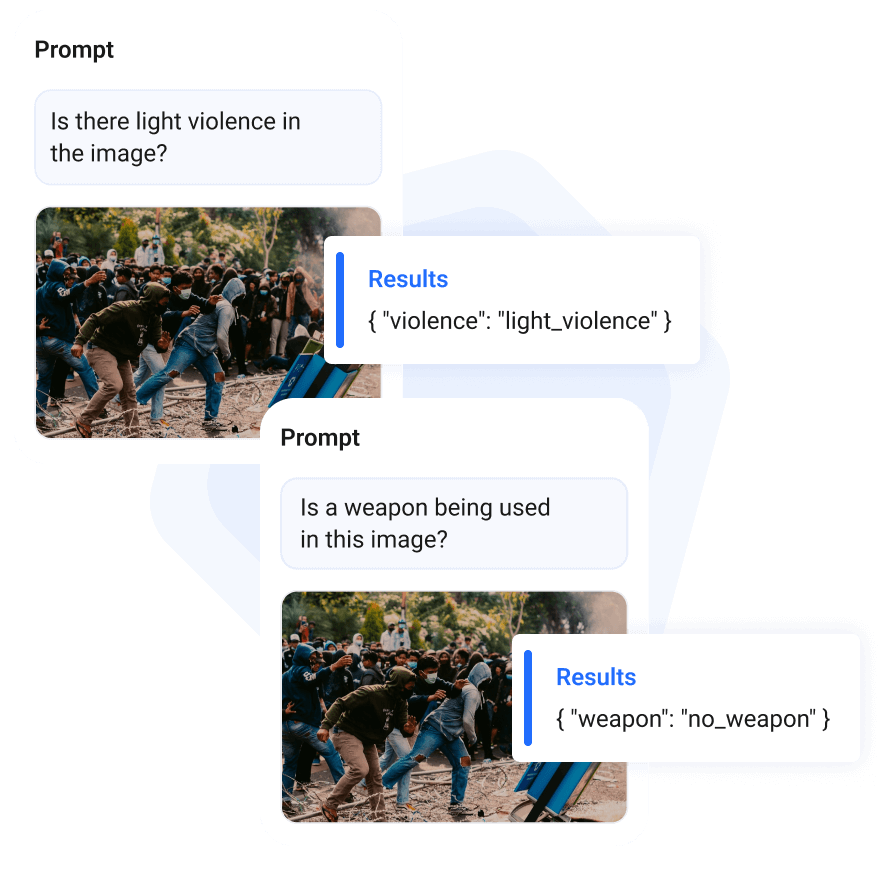
Moderation
Object Detection
Visual Q&A

Prompt
Ready to build something?
Leverage Hive VLM across wide ranging use cases
Leverage Hive VLM across wide ranging use cases
Content Moderation
Content Moderation
Object Detection
Visual Q&A
Age Verification
Celebrity Recognition
OCR

Content Moderation

Object Detection

Visual Q&A

Age Verification

Celebrity Recognition

OCR

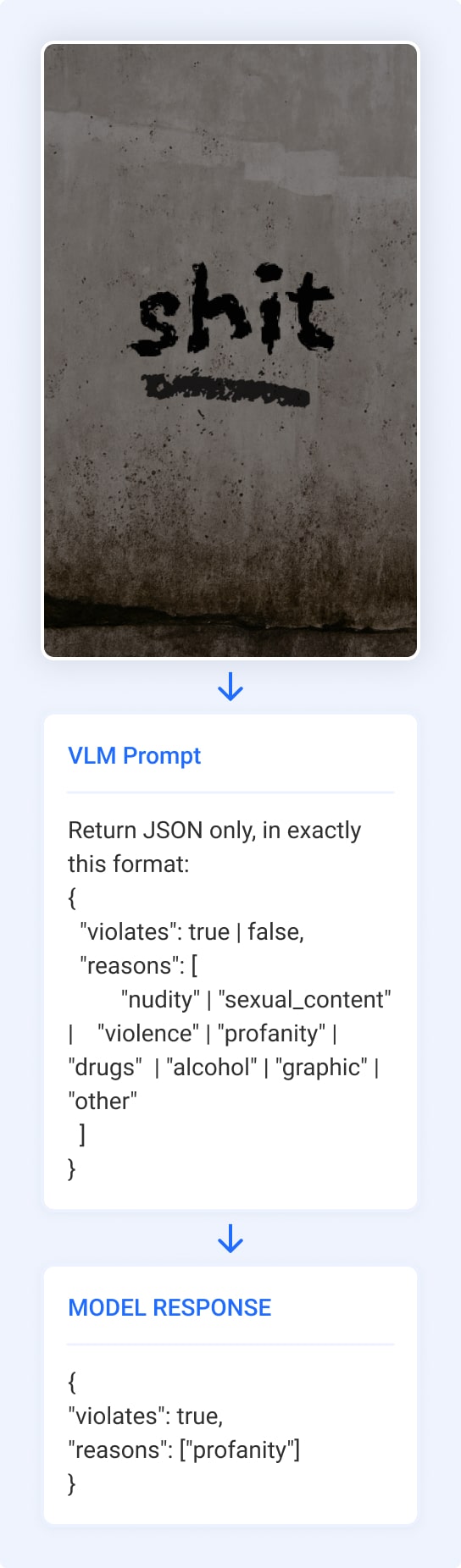
Developer-friendly integration
Developer-friendly integration
Connect in minutes, not months.
Our API is designed for hassle-free integration, with easy-to-use endpoints that let you submit images or entire videos and retrieve structured results.
Connect in minutes, not months.
Our API is designed for hassle-free integration, with easy-to-use endpoints that let you submit images or entire videos and retrieve structured results.
Why developers love Hive APIs
Why developers love Hive APIs

Simple, RESTful endpoints with fast, predictable responses.

Production-ready JSON that contains easily parseable labels and scores.

Developer docs with code samples, libraries, and quick start guides.
Usage-based pricing that grows with you
Usage-based pricing that grows with you
Start building with Hive VLM in minutes. When your traffic needs scale, upgrade to an Enterprise plan for higher throughput and custom support.
Start building with Hive VLM in minutes. When your traffic needs scale, upgrade to an Enterprise plan for higher throughput and custom support.

Built for
Developers
Perfect for small teams and early-stage projects

Built for
Enterprise
Premium capabilities and support for enterprises
