Hive
AutoML
AutoML
Build and deploy custom models fine-tuned to your unique needs—all without writing a single line of code. Integrate enterprise-grade image and text classification models into your production workflows in minutes.
See AutoML In Action
See AutoML In Action
About Hive AutoML
About Hive AutoML
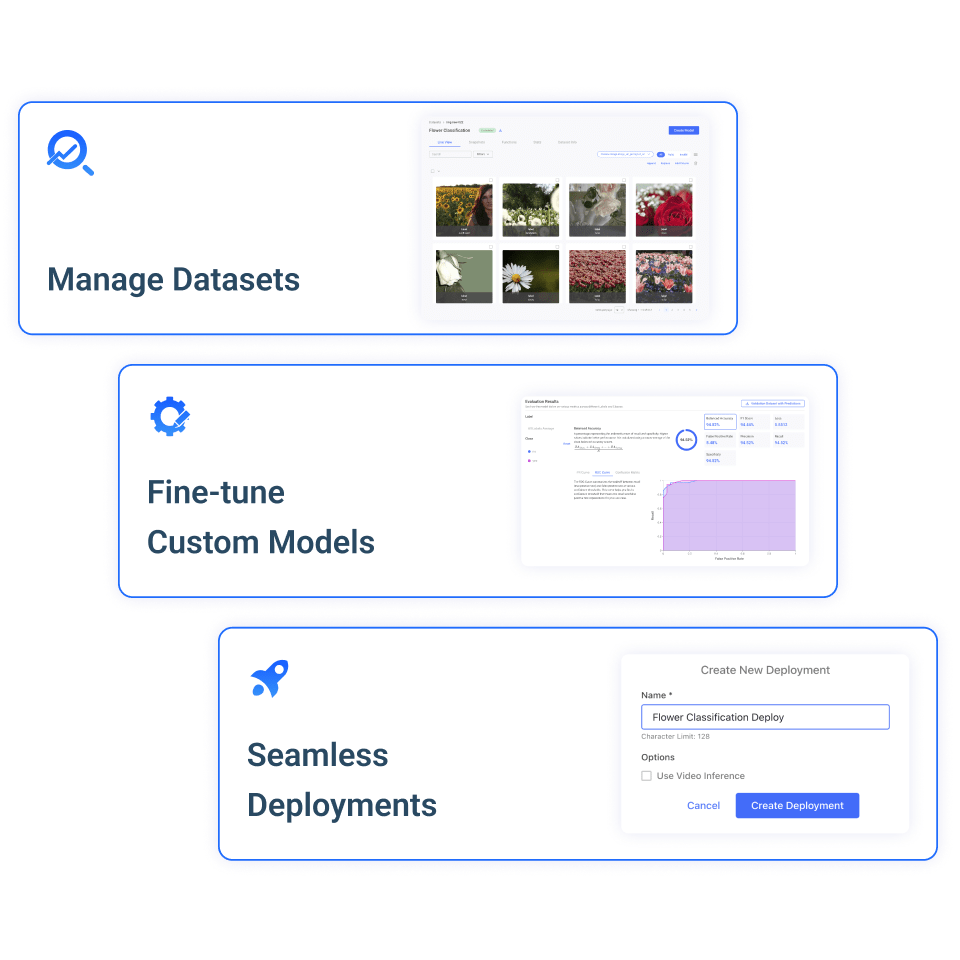
AutoML lets you easily manage your datasets, fine-tune custom models on that data, and deploy your custom models for inference.
Our no-code solution supports Hive's proprietary models as well as popular open-source models. AutoML offers models across a range of use cases including classification, sentiment analysis, moderation, and chat.
AutoML lets you easily manage your datasets, fine-tune custom models on that data, and deploy your custom models for inference.
Our no-code solution supports Hive's proprietary models as well as popular open-source models. AutoML offers models across a range of use cases including classification, sentiment analysis, moderation, and chat.
Manage Complex Data
Manage Complex Data
Data is the foundational building block for machine learning models. AutoML makes dataset management simple.
Data is the foundational building block for machine learning models. AutoML makes dataset management simple.
AutoML datasets make it simple to prepare your data for model fine-tuning. Our flexible platform accepts structured and unstructured data in several popular formats. You can upload data with existing labels or use our dataset management tools to add labels to uncategorized data.
AutoML also offers dataset functions and other popular tools to automate key data workflows. Functions can help you automate data labeling, set up an embedding pipeline for retrieval-augmented generation (RAG), and so much more.
Fine-Tune and Evaluate Custom Models
Fine-Tune and Evaluate Custom Models
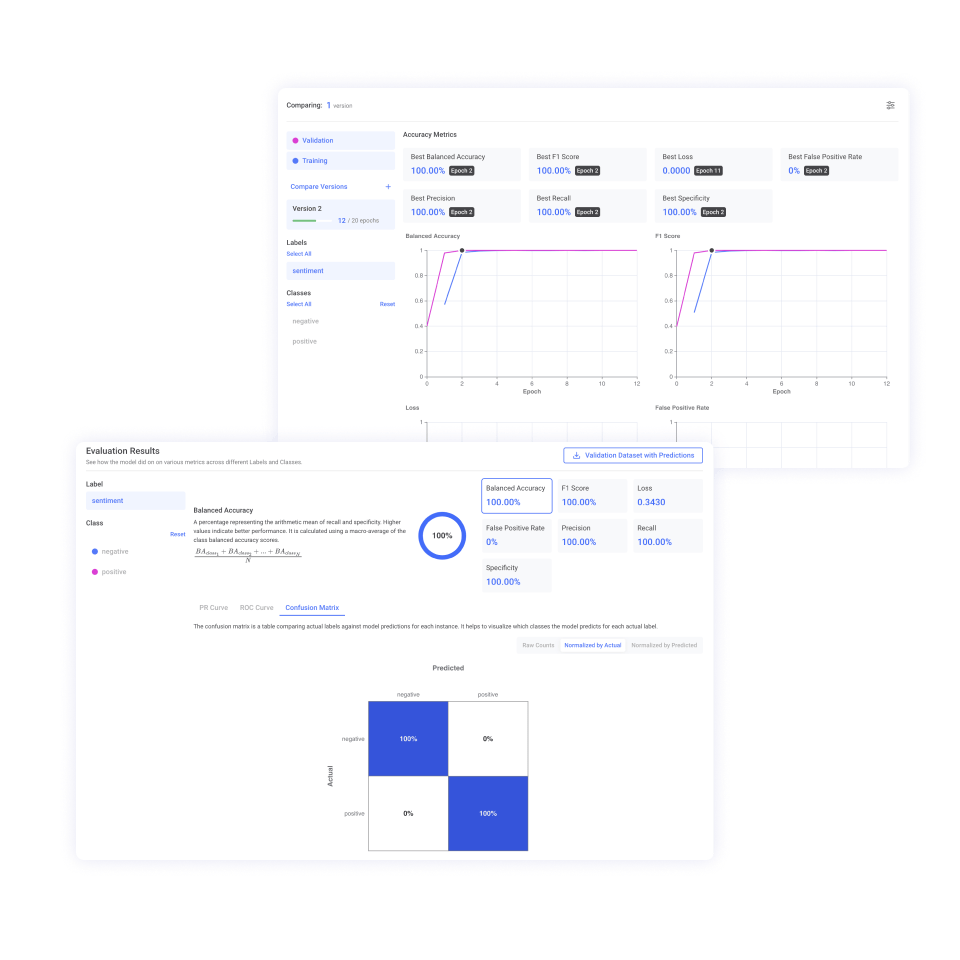
AutoML offers several text classification, image classification, and large language models for custom fine-tuning. We offer default training options that work well for most objectives. Users are also free to customize dozens of hyperparameters to better suit their needs or just to experiment with different training configurations.
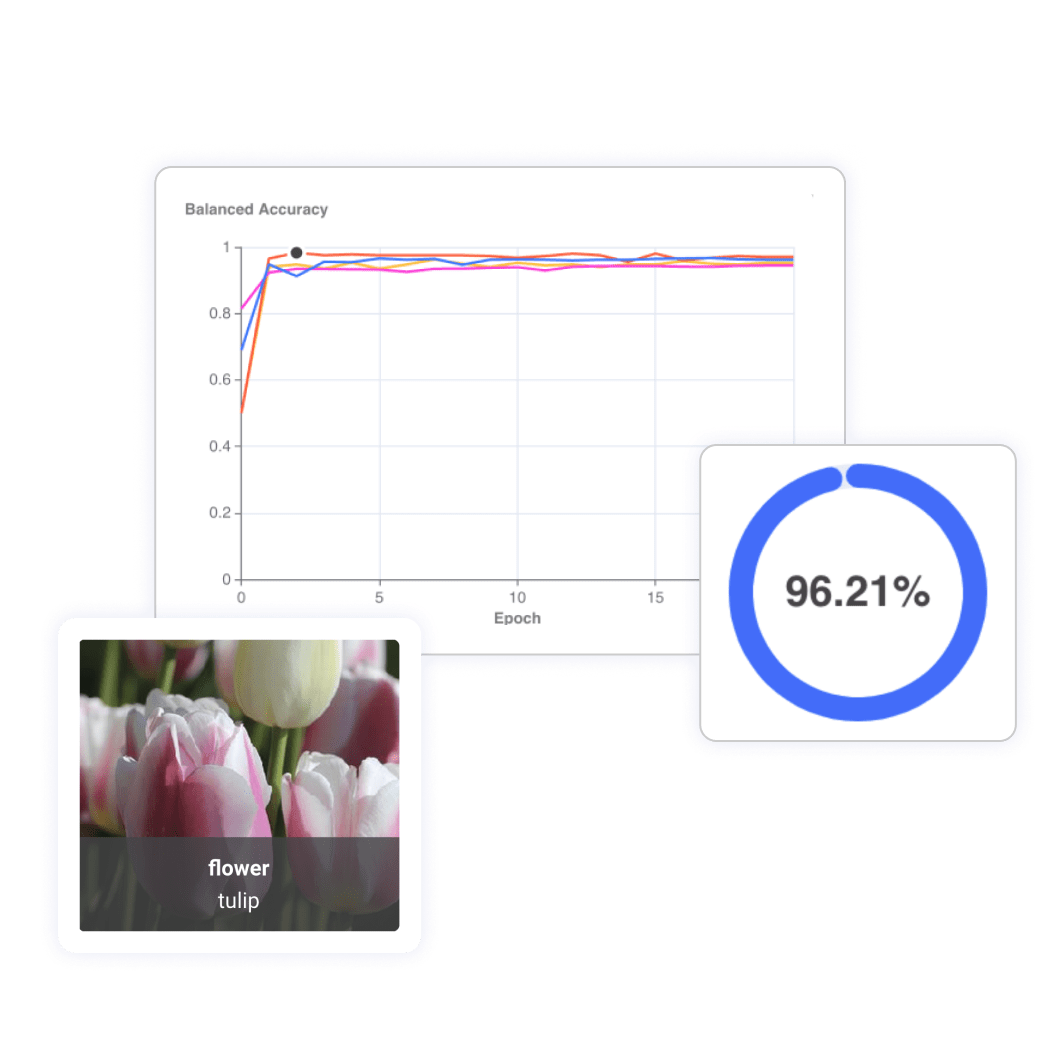
Several key metrics like balanced accuracy, precision, and recall are available during and after training to help you measure and evaluate your model’s performance.
Once you’ve trained and evaluated your model, deploy it to Hive Models with the click of a button. Your custom model will be available for inference and Moderation Dashboard integration through a Hive Models project, just like our pre-trained models.
AutoML offers several text classification, image classification, and large language models for custom fine-tuning. We offer default training options that work well for most objectives. Users are also free to customize dozens of hyperparameters to better suit their needs or just to experiment with different training configurations.
Several key metrics like balanced accuracy, precision, and recall are available during and after training to help you measure and evaluate your model’s performance.
Once you’ve trained and evaluated your model, deploy it to Hive Models with the click of a button. Your custom model will be available for inference and Moderation Dashboard integration through a Hive Models project, just like our pre-trained models.
Explore All Customizable Models
Explore All Customizable Models
Fine-tune a model to meet your specific needs with just a few clicks.
Fine-tune a model to meet your specific needs with just a few clicks.

Hive Text
Classification v3
Hive’s text classification model is able to interpret full sentences with linguistic subtleties across 30 different languages. It is a proprietary general-purpose text classification model trained by Hive’s Machine Learning team. Text Classification v3 is well-suited for most text classification tasks.
Hive Text
Moderation v3
Hive’s text moderation model is trained on a proprietary large corpus of labeled data across multiple domains, and is able to interpret full sentences with linguistic subtleties. The model detects undesirable content like sexual, bullying, spam, and more in 30 different languages. Fine-tuned versions of Hive Text Moderation v3 maintain pre-trained Hive moderation labels, so this model is best-suited for content moderation tasks.
DeBERTa v3
DeBERTa is a large text classification model. The DeBERTa v3 base model was pre-trained on English data. Though this model can be fine-tuned on any language, it is best suited for English-only datasets. DeBERTa performs well for sentiment analysis or very complex/nuanced classification.
Longformer
Longformer is a long-sequence transformer model. Its attention mechanism varies from similar transformer-based models, allowing it to process longer sequence lengths. Longformer is well-suited for classifying lengthy
text examples.Longformer is a long-sequence transformer model. Its attention mechanism varies from similar transformer-based models, allowing it to process longer sequence lengths. Longformer is well-suited for classifying lengthy text examples.
Simple usage based pricing so you only pay for what you use
Simple usage based pricing so you only pay for what you use
AutoML - Custom Training
Training
Text Moderation (Last Layer)
Text Moderation (Last Layer)
Contact Sales
Text Classification (Last Layer)
Text Classification (Last Layer)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (LoRA)
Text Classification (LoRA)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (Full Fine Tuning)
Text Classification (Full Fine Tuning)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (DeBERTa Last Layer)
Text Classification (DeBERTa Last Layer)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (DeBERTa LoRA)
Text Classification (DeBERTa LoRA)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (DeBERTa Full Fine Tuning)
Text Classification (DeBERTa Full Fine Tuning)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (Longformer Last Layer)
Text Classification (Longformer Last Layer)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Text Classification (Longformer Full Fine Tuning)
Text Classification (Longformer Full Fine Tuning)
$4.00 / 1M Rows Seen
$4.00 / 1M Rows Seen
Image Moderation (Last Layer)
Image Moderation (Last Layer)
Contact Sales
Image Classification (Last Layer)
Image Classification (Last Layer)
$40.00 / 1M Rows Seen
$40.00 / 1M Rows Seen
Image Classification (Full Fine Tuning)
Image Classification (Full Fine Tuning)
$40.00 / 1M Rows Seen
$40.00 / 1M Rows Seen
Object Detection (Last Layer)
Object Detection (Last Layer)
$40.00 / 1M Rows Seen
$40.00 / 1M Rows Seen
Inference
Text Moderation (Last Layer)
Text Moderation (Last Layer)
Contact Sales
Text Classification (Last Layer)
Text Classification (Last Layer)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (LoRA)
Text Classification (LoRA)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (Full Fine Tuning)
Text Classification (Full Fine Tuning)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (DeBERTa Last Layer)
Text Classification (DeBERTa Last Layer)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (DeBERTa LoRA)
Text Classification (DeBERTa LoRA)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (DeBERTa Full Fine Tuning)
Text Classification (DeBERTa Full Fine Tuning)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (Longformer Last Layer)
Text Classification (Longformer Last Layer)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Text Classification (Longformer Full Fine Tuning)
Text Classification (Longformer Full Fine Tuning)
$0.50 / 1000 Requests
$0.50 / 1000 Requests
Image Moderation (Last Layer)
Image Moderation (Last Layer)
Contact Sales
Image Classification (Last Layer)
Image Classification (Last Layer)
$3.00 / 1000 Requests
$3.00 / 1000 Requests
Image Classification (Full Fine Tuning)
Image Classification (Full Fine Tuning)
$3.00 / 1000 Requests
$3.00 / 1000 Requests
Object Detection (Last Layer)
Object Detection (Last Layer)
$1.50 / 1000 Requests
$1.50 / 1000 Requests
Data
Row Add
Row Add
$1.00 / 1000 rows added
$1.00 / 1000 rows added
File Add
File Add
$0.10 / 1 GB added
$0.10 / 1 GB added
Row Storage (Monthly)
Row Storage (Monthly)
$1.00 / 1000 rows hosted
$1.00 / 1000 rows hosted
File Storage (Monthly)
File Storage (Monthly)
$0.10 / 1 GB hosted
$0.10 / 1 GB hosted
- Uploaded datasets incur Row Add and/or File Add charges at the time of data upload.
- Row Storage and File Storage costs are billed at 12:01am UTC on the first day of each calendar month based on the number of rows and size of files stored on the AutoML platform at that time.
- Row Storage and File Storage monthly costs are not pro-rated.
Simple usage based pricing so you only pay for what you use
Simple usage based pricing so you only pay for what you use